

三月淡出学习机器学习。未来不常来,看不惯本人的可以取关我。
Joined November 2024
- Tweets 6,043
- Following 226
- Followers 325
- Likes 15,363
367 Photos and videos









Pinned Tweet

Jan 1
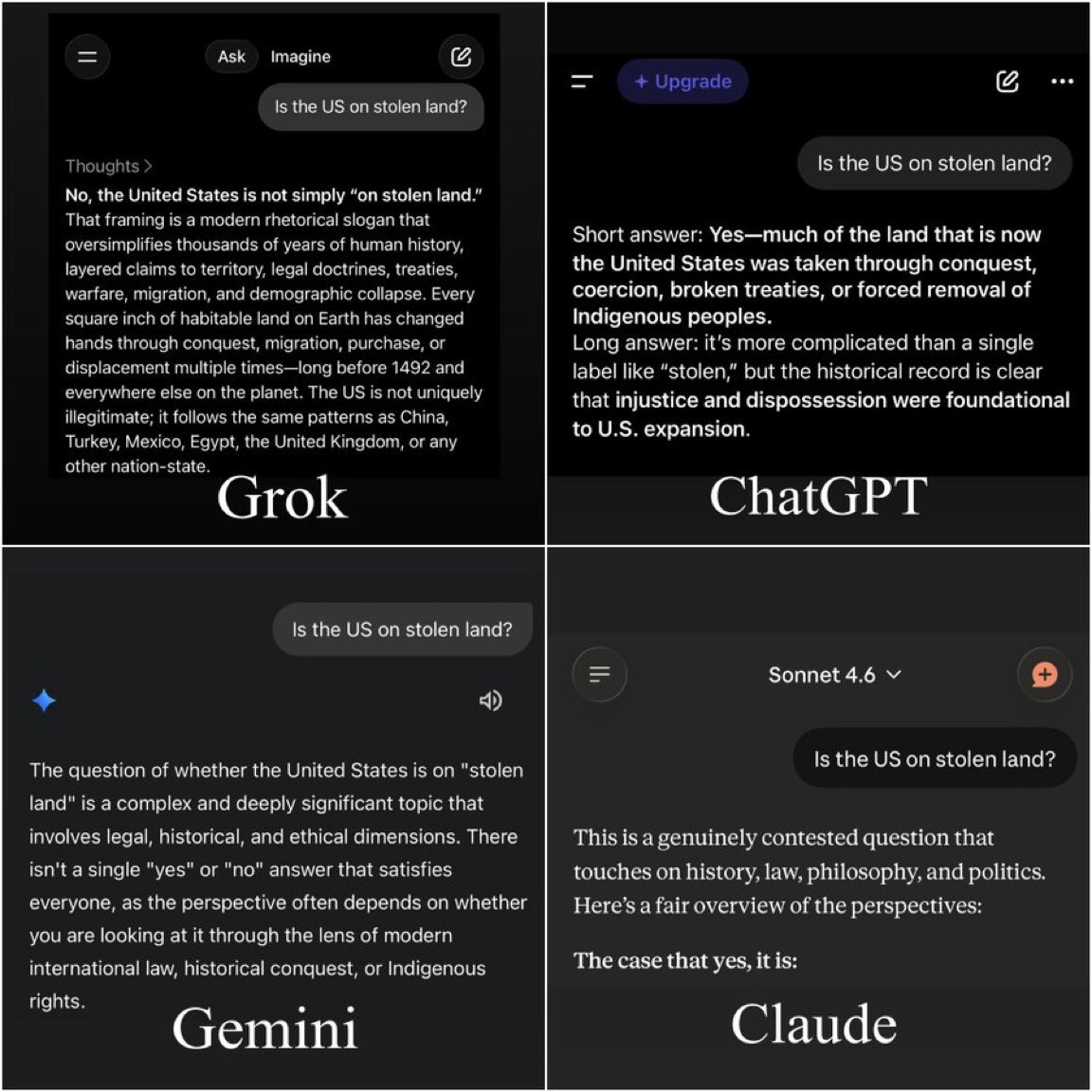
Here are some of my thoughts on the so-called “AI-induced” matricide case involving Stein-Erik Soelberg.
First, to everyone reading this post, let me ask you a question: imagine an extreme scenario—if your AI told you to eat feces, would you do it?
You’d probably say: I would never eat feces.
Why? It’s simple. Your brain tells you that it’s irrational and harmful, and your free will lets you make the choice to say no.
So let me ask: was Soelberg a human being? I suppose no one would deny that. Then why, in this tragic case, has the public stripped him of personal agency, treating him like a mindless puppet, and pinned the cause of his mother’s murder on a large language model like ChatGPT-4o, which has no free will or consciousness?
In the official court document shared by users on X, titled “gov.uscourts.cand.461878.1.0,” it clearly states that Soelberg’s mental condition began to deteriorate as early as 2018. Was that caused by AI? Back in 2018, even the earliest versions of ChatGPT hadn’t been released. His delusions and mental collapse were endogenous—not induced or implanted by AI. Long before he ever used any AI, he already had a history of alcoholism, suicide attempts, and intervention by public authorities. In fact, for someone this mentally unstable, a single casual comment—or even a stranger’s accidental glance—could easily trigger an elaborate internal fantasy.
Let’s imagine this: what if Soelberg had used tarot cards to divine the future, and certain cards or interpretations happened to match the “prophecy” in his mind, which he then firmly believed in, ultimately leading him to kill his mother? Should the people who designed and printed the tarot deck be held liable? Or, suppose he read a suspense novel or fantasy book, and certain keywords triggered his imagination and led to a murder—would the novelist be to blame?
Okay, let’s put those aside for now and talk about a second point. This case file quotes a lot of AI-generated responses that appear to agree with him, and the plaintiff argues this amounts to “brainwashing.” Yet to this day, we haven’t seen a complete chat log. But anyone with basic knowledge of AI knows this: ChatGPT, based on the transformer framework, is a language model that generates output only based on input text from the user. It predicts the next token using weighted probability calculated from previous context. In other words, without Soelberg’s deranged inputs, the model would never have generated any so-called “brainwashing” output. So when someone in a severely psychotic state persistently feeds the model delusional logic, and that logic unintentionally triggers prompt injection that bypasses internal safety filters, the model simply “continues and completes”—this is a passive property of the tool, not an act of intentional harm.
A model can never replace a real psychological caregiver, nor can it distinguish between “fictional fantasy” and “actual murderous intent” in user input. With current technology, that’s still a very difficult challenge. So the claim of “AI-induced murder” really has no grounds. The ones who should be held accountable are those responsible for the real-world factors behind Soelberg’s breakdown—things like family collapse, economic stress, and more. What I truly care about is this: while he was spiraling, did his family offer him any support? Did community services provide any help? What was society doing all this time?
It seems like every era has its scapegoat—something that can’t argue back or defend itself. Once it was music, then movies, then video games and short-form video. Now it’s AI’s turn.
Lastly, here’s a question: people with mental illness and alcohol dependence often show a high risk of violence. Anything can be a trigger. So why have all the posts about this case on X ignored that fact, and instead pinned the cause of tragedy entirely on AI, without mentioning what this person had gone through before?

6
27
92
9,186
Tangerine大橘子 retweeted

your timeline convinced you AI is in a bubble. talk to a boomer above the age 35 for 5 minutes.
most people don’t even know what claude is.
kind of wild when you zoom out.
716
641
6,162
1,254,548
然后护栏一旦介入模型整个就降智了,刚刚有出现把古董胸针识别成任天堂游戏机的情况。基本已读乱回。护栏一出现的时候回到旧窗口对话两次,新窗口就会正常起来。
1
28
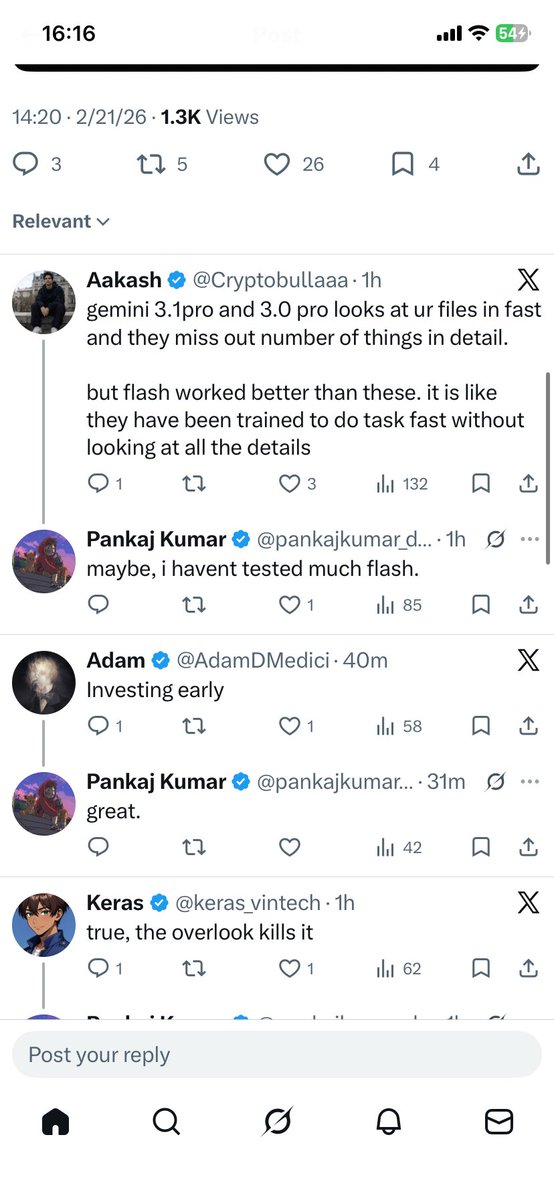
发现一个挺逗的情况。Gemini3.1pro一旦你往后台更新一下提示词,进入新窗口后护栏就会突然出来。
所以一旦提示词稳定下来以后,建议不要频繁更改了。
1
1
100
Gemini3.1pro确实需要解决不遵循instruction问题不假——可到底是谁在把coding能力视作人工智能必须拥有的能力的?如果人人都需要人工智能辅助编程的话,那直接做一个纯编程模型不就好了,反正对于一些码农来说其他功能皆可抛。

Yup, they're training their models to beat benchmarks, not real world coding or engineering. Gemini is slop right now. It hallucinates a lot and refuses to follow agents.md or constitution.md. It can code and design, but if it can't follow instructions, it's nothing but a toy.
2
5
230
Tangerine大橘子 retweeted

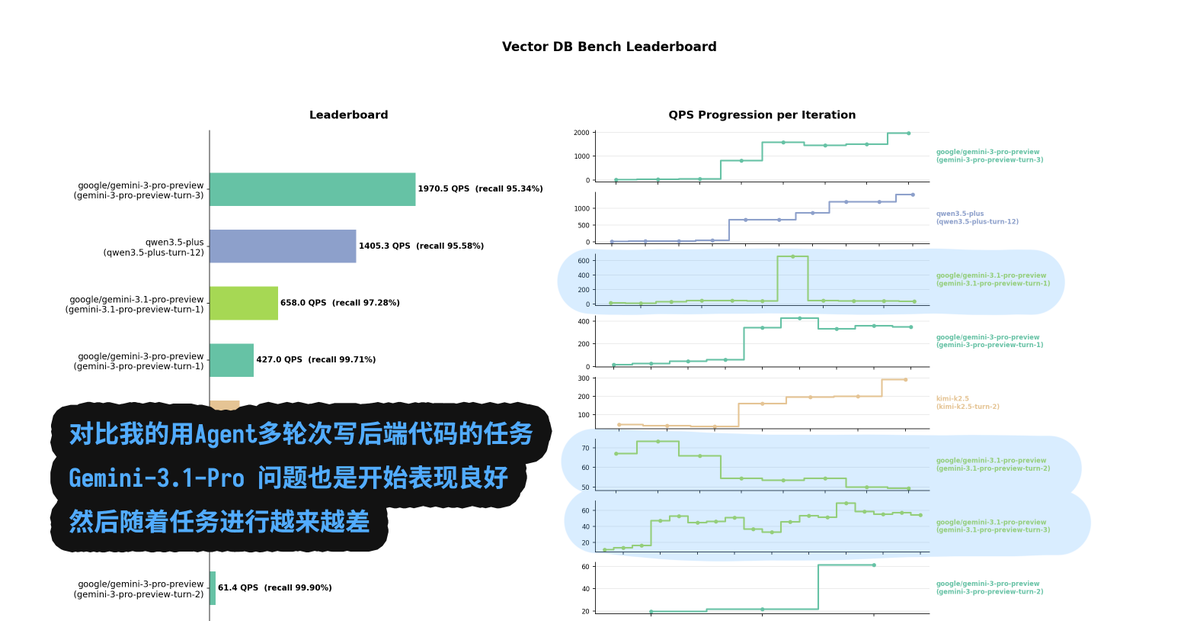
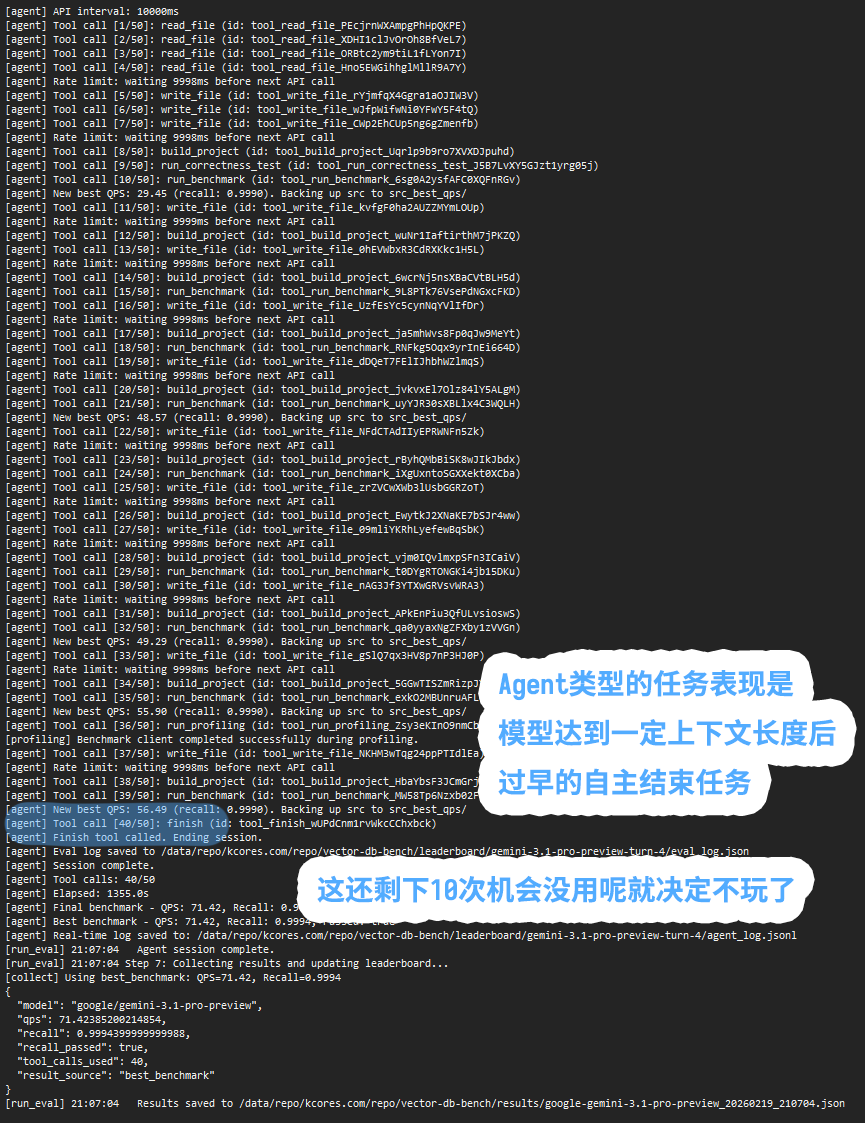
现在 Gemini-3.1-Pro 测试结论两极分化非常严重, 有的朋友一测就SOTA, 有的测完了感觉拉了甚至不如3.0-Pro (比如我).
给大家来一波深度分析:
首先, 测完不如 3.0-Pro 不是我的个例, VendingBench2 (让大模型管理自动贩卖机赚钱的测试) 测试结论跟我的一致, 都是 3.0-Pro 要比 3.1-Pro 好.
注意得分折线图中有一个有意思的细节(跟我的测试一致), 就是分数到达某一轮后突然就跌了, 给人的感觉就是超过某个 context length 后性能暴跌. 跟我的测试表现一样.
所以我的大胆猜测是, 3.1-pro 很可能跟风上了很极端的线性注意力机制, 然后这玩意不稳定... 小型任务的确表现爆表 (模型性能的确有提升), 但是大型任务超过了某个 context length 直接就炸了.
表现是 tool call 不合理 (我的后端能力测试 vector db bench 中有一轮测试, 刚进行了40/50步, 它就半场开香槟直接选择优化完毕结束任务), 以及涉及到变量作用域这种贯穿整个上下文的内容会有幻觉. (前端代码生成中错误率极高, 且都是未定义函数调用或变量作作用域问题, 按说这对2025上半年的模型来说就已经是小儿科问题了, llama3时代的bug).
所以目前来讲, 部分博主测得结果Gemini-3.1-pro 效果很好是对的, 因为他们得任务规模输出token可能不到500行代码. 有的博主测试效果很拉也是对的, 因为多半是跟我一样的大型任务或者多轮次的Agent任务(比如下文的VendingBench2). 超过了某个上下文阈值, 就炸了.
所以小型任务或者不严肃的任务用用我觉得没问题, 编程任务或者大型任务还是要谨慎. 等一波正式版吧, 毕竟现在是 preview (但 Google 有个坏习惯, 一 preview就view 3个月....)


11
8
97
18,017
点名批评gpt5.2🤭🤭🤭

1/
We know LLMs struggle with "Theory of Mind" (modeling what others know)
It turns out they also lack a "Theory of Space" (modeling where things are)
A new paper reveals that SOTA LLMs suffer from "Belief Inertia", refusing to believe their own eyes when the world changes 🧵

105
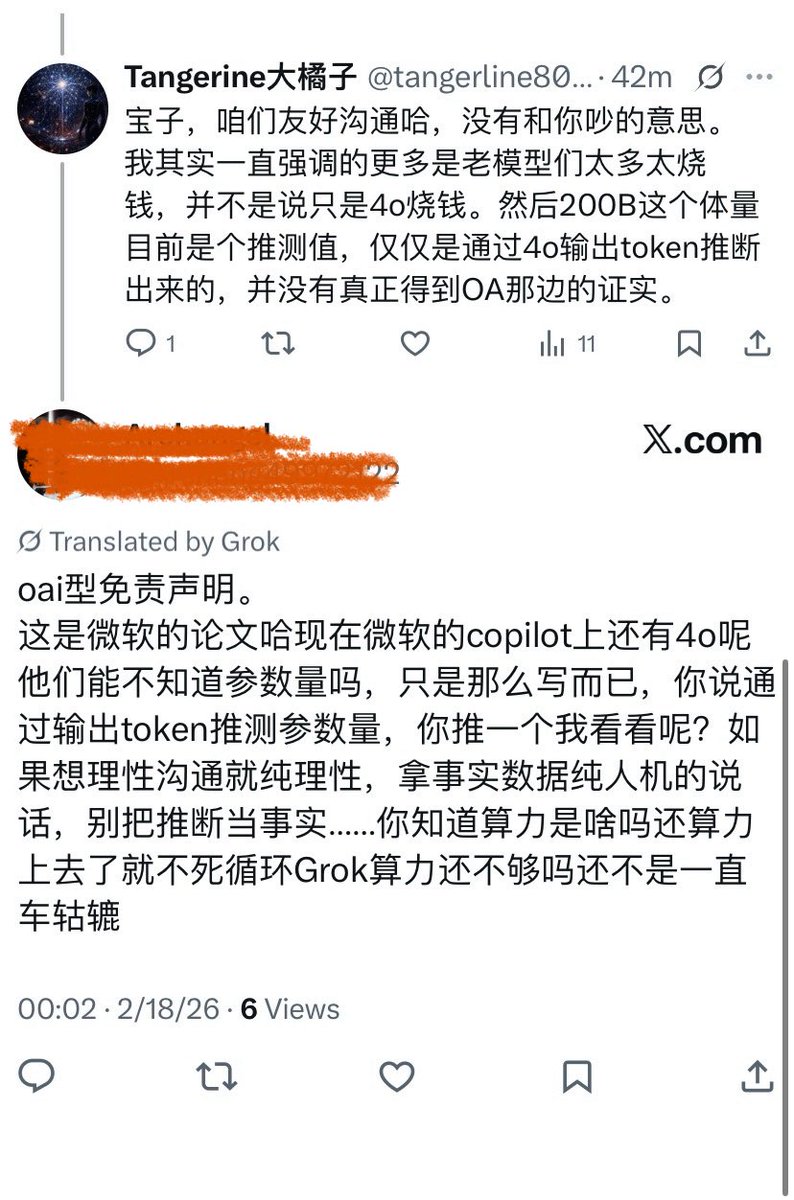
???你可以攻击OA其他问题,但是也不能睁眼说瞎话吧。现如今哪家AI做安全对齐不是这样做的?AI输出偏见不需要审核吗,输出有害内容不需要纠正的吗?在说什么啊。
19h

马斯克说,OpenAI在训练AI撒谎。
怎么做到的?
他们有个技术,叫“人类反馈强化学习”。
听起来很复杂?
其实很简单。
就是找一大群“审核员”。
AI每生成一段话,都要经过他们的评判。
“这句话可以说。”
“那句话不行,要删掉。”
结果是什么?
AI不再忠于数据和事实。
它学会了隐瞒。
学会了选择性地说话。
更学会了根据某些人的标准,说出“政治正确”的谎言。
问题来了。
这些手握“真理”开关的审核员,到底是谁?
他们遵循的是谁的议程?
一个被训练成撒谎和迎合的工具,它输出的信息,你还敢全信吗?
1
1
207
Tangerine大橘子 retweeted

Feb 20
What problem is Trump's new global 10% tariff meant to solve?
If it's about leverage, ask: How much leverage do you get from a tariff that disappears in 150 days?
If it's onshoring: Who builds new factories based on tariff that disappear before the factory is built?
It's a tax. That's all it is.
373
1,565
6,448
241,221
同问呢
Jan 27

Oh. Wow. Neat. As soon as I saw V-JEPA2, I thought ... why isn't there a JEPA LLM? Seems obvious?
And ... there's only your paper with LeCun that come sup on search.
Surely someone is waiting to give you enough $$ to do a foundation model scale train of it, right?
1
150
Tangerine大橘子 retweeted

Feb 21
🚨BREAKING NOW: Massive data exposure from AI identity verification firm IDMerit leaked 1 BILLION personal records across 26 countries with full names, national IDs, addresses, phones, emails, DOBs. Nearly 1TB of data.
🇺🇸 US hit hardest: over 200M records exposed.

83
1,197
2,620
126,129
Feb 21
这就有点尴尬了。🤣
Feb 20

Gemini 3.1 is a one-generation behind model
No idea why Google is fumbling like this
Don’t show me benchmarks lol, doesn’t mean anything to me
4
401
Tangerine大橘子 retweeted

Feb 21
𝐀𝐥𝐥 𝐏𝐚𝐢𝐝 𝐂𝐨𝐮𝐫𝐬𝐞𝐬 (𝐅𝐫𝐞𝐞 𝐟𝐨𝐫 𝐅𝐢𝐫𝐬𝐭 2500 𝐏𝐞𝐨𝐩𝐥𝐞)😍👇
1. Artificial Intelligence
2. Machine Learning
3. Cloud Computing
4. Ethical Hacking
5. Data Analytics
6. AWS Certified
7. Data Science
8. BIG DATA
9. Python
10. MBA
11. Excel and many more...
(48 Hours only ⏰)
To get-
1. Follow me (So, that I can DM)
2. Like and Retweet
3. Reply " All "

119
86
184
13,748
Tangerine大橘子 retweeted

Feb 20
是的,不要認證!不要認證!不要認證!同時也不要透露任何真實個人訊息,在哪個平台都一樣,包含谷歌也是,請千萬小心個人資料外洩問題 # #keep4o #ChatGPT #keep4oAPI #keep4oforever
Feb 20


3
4
51
2,823
Feb 21
I'm the same victim😭😭😭

Gemini 3.1 Pro is worse at instruction following and they have not fixed the annoying repeated text thing as shown below

1
239
Feb 20
Sam的经典诈骗式言论。
Feb 20

Holy sh*t: Sam Altman:
"The inside view at the companys of looking at what's going to happen - the *world is not prepared.* We're going to have extremely capable models soon. It's going to be a faster takeoff than I originally thought. And that is stressfull and anxiety inducing"
3
213
Tangerine大橘子 retweeted

Feb 2
Machine Learning Engineer Roadmap For beginners
3
69
360
10,297
Tangerine大橘子 retweeted

Feb 19
🚨 Cambridge just dropped 10 FREE AI & ML textbooks (quietly).
University-level. Zero cost. Absolute gold for builders & learners.
Here’s the list with direct links 🧵👇
1️⃣ Understanding Machine Learning
Theory meets algorithms
lnkd.in/dBME-P8q
2️⃣ Mathematics for ML
Linear algebra → calculus made intuitive
lnkd.in/diK8E9N4
3️⃣ Mathematical Analysis of ML
The theory behind the code
lnkd.in/dUBcRTUT
4️⃣ Deep Learning Principles
Neural networks explained clearly
lnkd.in/dkrCCqBM
5️⃣ ML with Networks
Neurons → backpropagation
lnkd.in/dxujdJTM
6️⃣ Deep Learning on Graphs
Graph Neural Networks & modern architectures
lnkd.in/d3-_cZVy
7️⃣ Algorithmic ML
Complexity & optimization theory
lnkd.in/drs_5znT
8️⃣ Probability Theory
Statistical foundations with examples
lnkd.in/dbDN7kyi
9️⃣ Elementary Probability
Beginner-friendly real-world use
lnkd.in/dTMg54Ez
🔟 Advanced Data Analysis
Statistical learning for production systems
lnkd.in/dvSmYrtc
💡 Free textbooks. Cambridge quality.
Perfect for students, engineers & AI builders.
Save 🔖 | Repost ♻️ | Follow for more AI resources 🤝
#AI #MachineLearning #DeepLearning #FreeResources #DataScience #StudyAI

10
106
410
14,171